Brain2Music: Reconstructing Music from Human Brain Activity
Authors anonymized
Abstract The process of reconstructing experiences from human brain activity offers a unique lens into how the brain interprets and represents the world. In this paper, we introduce a method for reconstructing music from brain activity, captured using functional magnetic resonance imaging (fMRI). Our approach uses either music retrieval or the MusicLM music generation model conditioned on embeddings derived from fMRI data. The generated music resembles the musical stimuli that human subjects experienced, with respect to semantic properties like genre, instrumentation, and mood. We investigate the relationship between different components of MusicLM and brain activity through a voxel-wise encoding modeling analysis. Furthermore, we discuss which brain regions represent information derived from purely textual descriptions of music stimuli.
Music Reconstruction with MusicLM (Highlights)
| Stimulus (GTZAN music) | Reconstructions (generated by MusicLM) | ||
|---|---|---|---|

Comparison of Retrieval and Generation
| Stimulus | Retrieval | Generation with MusicLM | ||
|---|---|---|---|---|
| GTZAN music | From FMA | Gen #1 | Gen #2 | Gen #3 |
Comparison Across Subjects
| Stimulus | Retrieval (FMA) | Generation (MusicLM) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Stimulus | Subject 1 | Subject 2 | Subject 3 | Subject 4 | Subject 5 | Subject 1 | Subject 2 | Subject 3 | Subject 4 | Subject 5 |
Encoding: Whole-brain Voxel-wise Modeling
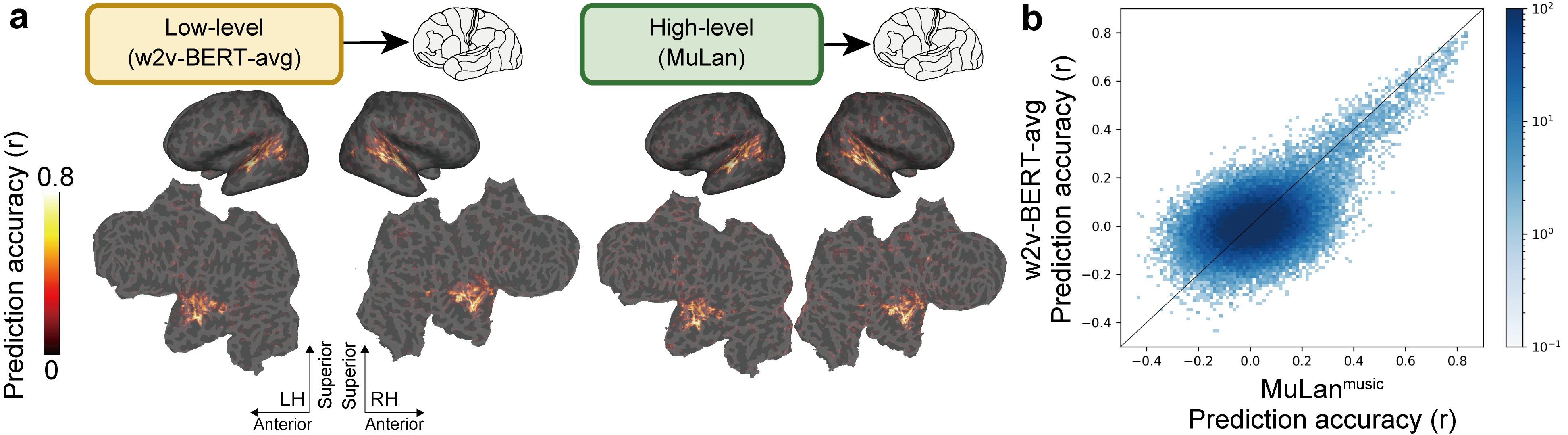
By constructing a brain encoding model, we find that two components of MusicLM (MuLan and w2v-BERT) have some degree of correspondence with human brain activity in the auditory cortex.
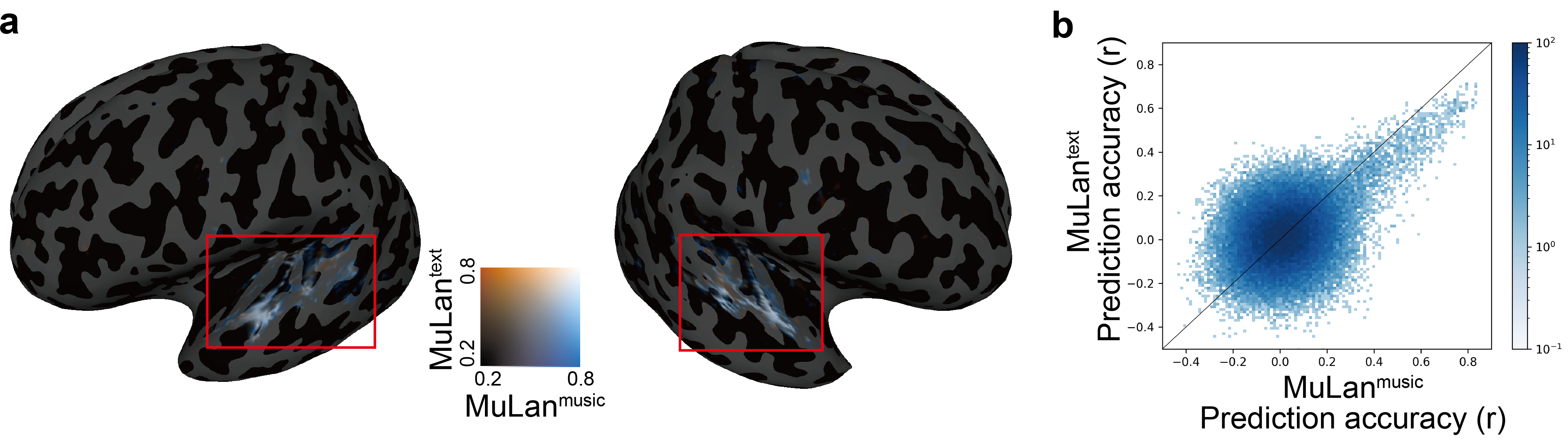
We also find that the brain regions representing information derived from text and music overlap.
GTZAN Music Captions
We release a music caption dataset for the subset of GTZAN clips for which there are fMRI scans. Below are ten examples from the dataset.
| Clip name | GTZAN music (15s slice) | Human-written text caption |
|---|---|---|
| blues.00017 | It is lazy blues with a laid-back tempo and relaxed atmosphere. The band structure is simple, with the background rhythm punctuated by bass and guitar cutting. The impressive phrasing of the lead guitar gives the piece a nostalgic impression. | |
| classical.00008 | Several violins play the melody. The melody is simple and almost unison, but it moves between minor and major keys and changes expression from one to the other. | |
| country.00012 | This is a classic country song. You can hear clear singing and crisp acoustic guitar cutting. The wood bass provides a solid groove with a two-beat rhythm. This is country music at its best. Ideal for nature scenes and homely atmospheres. | |
| disco.00004 | This music piece has a disco sound. Vocals and chorus create extended harmonies. The synthesiser creates catchy melodies, while the drumming beats rhythmically. Effective tambourine sounds accentuate the rhythms and add further dynamism. This music is perfect for dance parties, club floors and other scenes of dancing and fun. | |
| hiphop.00014 | This is a rap-rock piece with a lot of energy. The distorted guitars are impressive and provide an energetic sound. The bass is an eight beat, creating a dynamic groove. The drums provide the backbone of the rhythm section with their powerful hi-hats. The vocal and chorus interaction conveys tension and passion and draws the audience in. | |
| jazz.00040 | This is medium-tempo old jazz with female vocals. The band is a small band similar to a Dixie Jazz formation, including clarinet, trumpet and trombone. The vocal harmonies are supported by a piano and brass ensemble on a four beat with drums and bass. | |
| metal.00026 | This is a metal instrumental piece with technical guitar solos and distortion effects. The heavy, powerful bass creates a sense of speed, and the snare, bass and guitar create a sense of unity in unison at the end. It is full of over-the-top playing techniques and intense energy. | |
| pop.00032 | Passionate pops piece with clear sound and female vocals. The synth accompaniment spreads out pleasantly and the tight bass grooves along. The beat-oriented drums drive the rhythm, creating a strong and lively feeling. Can be used as background music in cafés and lounges to create a relaxed atmosphere. | |
| reggae.00013 | This reggae piece combines smooth, melodic vocals with a clear, high-pitched chorus. The bass is swingy and supports the rhythm, while whistles and samplers of life sounds can be heard. It is perfect for relaxing situations, such as reading in a laid-back café or strolling around town. | |
| rock.00032 | This rock piece is characterised by its extended vocals. The guitar plays scenically, while the bass enhances the melody with rhythmic fills. The drums add dynamic rhythms to the whole piece. This music is ideal for scenes with a sense of expansiveness and freedom, such as mountainous terrain with spectacular natural scenery or driving scenes on the open road. |